Full-Stack Observability: Warum geht es künftig kaum mehr ohne?
Wie die Ergebnisse der globalen Studie „Agents of Transformation 2021: The Rise of Full-Stack Observability“ des Cisco-Unternehmens AppDynamics zeigen, wurden digitale Transformationsprojekte in der Pandemie dreimal schneller umgesetzt als sonst. Die IT-Abteilungen stehen dadurch unter einem enormen Druck. Auch schon vor Corona wurden digitale Schnittstellen mit Kunden, Partnern und Mitarbeitern immer selbstverständlicher und in neue Business Modelle integriert. Die neue Leichtigkeit am Frontend bedeutet jedoch eine geradezu explodierende Komplexität der erforderlichen Technik im Hintergrund.

95% ...der Technologen geben an, dass es wichtig ist, einen Überblick über den gesamten IT-Bereich zu haben.
96% ...der Technologen weisen auf die negativen Folgen hin, die sich ergeben, wenn sie keine echte Transparenz und keinen Performance-Einblick des gesamten Technologie-Stacks haben.
76% ...der Technologen räumen ein, dass sie es sich nicht mehr leisten können, sich bei Performance-Themen auf ihr Bauchgefühl zu verlassen. Nicht, wenn sie mit dieser hohen Komplexität konfrontiert sind - sie brauchen genaue Echtzeitdaten.
Quelle: Studie "Agents of Transformation 2021: The Rise of Full-Stack Observability", AppDynamics
Was bedeutet Full-Stack Observability?
Der Begriff Full-Stack Observability steht im Kern für die Fähigkeit, jederzeit einen vollumfänglichen Einblick in den gesamten Software Stack, die Infrastruktur und das Netzwerk zu haben. Ziel ist die Absicherung einer optimalen Performance. „Ganzheitlichkeit“ ist ein wichtiges Stichwort in diesem Zusammenhang, denn einzelne Monitorings können ein falsches oder zumindest unscharfes Bild liefern und schlussendlich keine optimale Nutzererfahrung sicherstellen. Wenn beispielsweise die Datenbank und die CPU gleichzeitig knapp unterhalb ihrer Belastungsgrenze laufen, scheint noch kein Handlungsbedarf gegeben zu sein. Tatsächlich aber sorgt die zweifache, hohe Auslastung für eine Verlangsamung der Applikation.
Wie lässt sich die Full-Stack Observability erreichen?
Für einen umfassenden Einblick müssen Software, Hardware und Netzwerk gleichermaßen in den Blick genommen werden. Es gilt das seit Jahrzehnten eingeübte Silo-Denken durch eine komfortable, ganzheitliche Lösung zu überwinden, um die Geschäftsziele (gute Customer Experience, stabile Umsatzzahlen, Kostenkontrolle, etc.) dauerhaft zu erreichen. Eine Kombination aus drei Cisco-Tools steht dafür als Gesamtlösung zur Verfügung.
- A) Für das Monitoring, die Analyse und die Verwaltung von Softwareanwendungen wird Application Performance Management nötig. Es ruht im Idealfall auf drei Säulen: Visualisierung der unterschiedlichen Datenquellen, Ermittlung siloübergreifender Erkenntnisse mittels KI und Automation entsprechender Reaktionsmaßnahmen. Die APM-Lösung von AppDynamics bietet all diese Instrumente. Sie ermöglicht es unter anderem, Problemursachen unmittelbar ausfindig zu machen, sodass Ausfallzeiten minimiert und wiederkehrende Vorfälle, über ein automatisiertes Baselining, im Laufe der Zeit sogar vermieden werden können.
- B) Konsequenterweise muss die Full-Stack Observability auch die Hardware mit einbeziehen, insbesondere wenn diese virtualisiert sein sollte. Sinnvoll ist daher ein nachgeschaltetes ARM-Tool (Application Resource Manangement). Es sorgt dafür, dass Ressourcen automatisch überall dort allokiert und optimiert werden, wo eine APM-Lösung wie AppDynamics Probleme identifiziert hat. Der Intersight Workload Optimizer (IWO) analysiert in Echtzeit sowohl die Auslastung von Rechenzentren und Nutzung von Clouds als auch die aktuell tatsächlich benötigen Ressourcen für die einzelnen Anwendungen und gibt entsprechende Handlungsempfehlungen oder optimiert Ressourcen vollautomatisiert und eigenständig.
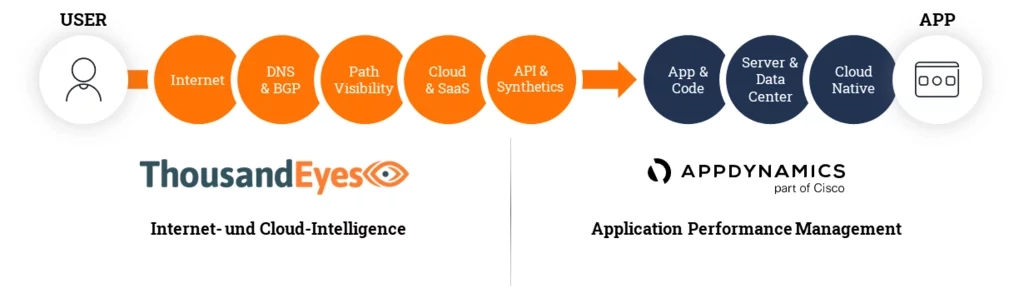
- C) Um hinter die eigene Infrastruktur zu schauen, braucht es ein weiteres Tool in Form von Network Intelligence: ThousandEyes setzt die Arbeit von AppDynamics sozusagen auf Streckenebene fort und ermöglicht über das unternehmenseigene Netzwerk hinaus Einblicke in ISP-Netzwerke, Public Cloud und UCaaS. Auf ihrer gesamten Länge (End-to-End) lassen sich Probleme oder Schwächen bestimmen. In Zeiten, in denen verteilte Umgebungen massiv zunehmen, bekommt diese Möglichkeit besonderes Gewicht. Das Tool schließt die Sichtbarkeits-Lücken, die bei einer reinen APM-Lösung bestehen blieben und verbindet aktive und passive Techniken des Monitorings, um nur einige wenige Vorzüge zu nennen.
Warum ist Logicalis der richtige Ansprechpartner in Sachen Full-Stack Observability?
Logicalis ist einer von nur fünf globalen Cisco Gold Partnern und verbindet mit dem Hersteller eine langjährige strategische Partnerschaft mit dem Vorteil, dass sie führende Technologieprodukte mit einem bewährten Integrations- und Serviceteam ergänzen. Als Digitalisierungspartner und zertifizierter Cisco Advanced Technology Provider sowie Advanced Customer Experience Spezialised Partner besitzt Logicalis umfangreiches Consulting- und Service-Knowhow unter anderem in den Bereichen Data Center, Digitale Transformation und Networking. Die Lifecycle-Service-Teams von Logicalis sind für das gesamte Portfolio der Cisco-Technologien zugelassen.
Sie haben Fragen oder benötigen weitere Informationen? Unsere Logicalis Experten stehen Ihnen gerne zur Verfügung. Sprechen Sie uns an!
